了解了RDD概念后,介绍下Spark的工作机制:
1、惰性计算
首先,值得一提的是,Spark的RDD的Transformation操作都是惰性计算的,也就是只有在执行Action操作的时候才会真正开始计算。转化操作不会立刻执行,而是在内部记录下所要执行的操作的相关标识,等到了Action操作后再执行,Spark的这一个特性也叫做惰性计算。
这样有什么好处呢?举个例子,假如textFile读取文件数据,通过flatMap按照空格分隔后,再用fitler方法根据关键字过滤,最后调用first()返回数据集第一个元素,如果中途每个操作都要产生新的 RDD,那势必会浪费很多内存空间,所以Spark在调用first操作的时候,才会正常的执行计算,因此,我们调试Spark程序时,当断点打在Transformation操作的函数中时,有时候会无法进入,只有当调用了Action操作时,才会真正执行。
2、Spark应用执行组件
Spark应用的运行方式分为Cluster模式和Client模式,其中Client模式是指Driver Program在任务提交机上执行,适用于交互和调试,也就是希望快速看到计算结果;而Cluster模式运行在ApplicationMaster中,一般应用在生产过程中。
这里先解释一些涉及的基本组件的概念:
Application:用户自定义的Spark程序,包含1个Driver Program和若干个Executor进程。
Driver Program:运行Application的main()函数并且创建SparkContext,是应用的主控进程,负责应用的解析、切分Stage并调度Task到Executor进程上执行。
SparkContext:是spark应用程序的入口,负责调度各个运算资源,协调各个work node上的Executor。
Executor:是Application运行在work node上的一个进程,负责运行Task,一般每个Application都有各自独立的executors,不同application的executor若不通过外部存储,是无法进行数据交互的。
Master:集群中的含有Master进程的节点,用于控制、管理和监督整个spark集群。
Client:客户端节点,负责客户端进程,提交job到master。
Work Node:集群的工作节点,接受Master的指令,运行Application的代码,并向Master汇报进度。
Task:任务,一般一个RDD分区对应一个Task,是单个分区上最小的处理流程单元。
TaskSet:一组关联的,但相互之间没有Shuffle依赖关系的Task集合。
Stage:一个taskSet对应的调度阶段,每个job会根据RDD的宽依赖关系被切分很多Stage,每个stage都包含 一个TaskSet。
Job:由Spark Action操作触发的作业。
Spark几个运行组件的关系如图1所示:
3、Spark应用执行流程
Spark的应用提交有2种模式,一个是Driver进程在客户端运行,一个是Master节点指定Driver进程在某个Work节点运行。
(1)Driver进程在客户端运行
执行流程如图2所示,
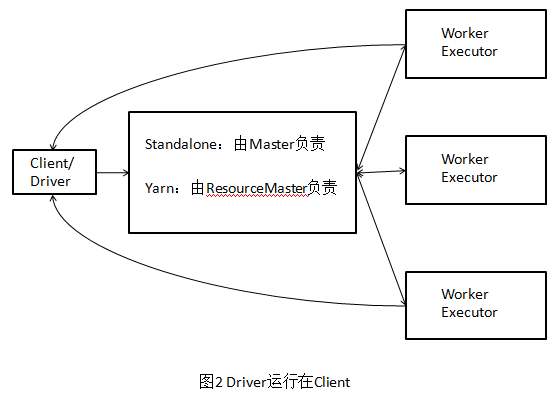
- Client端启动Driver进程,在Driver中启动或实例化DAGScheduler等组件。
- Worker向Master注册,Master通过指令让Worker启动Executor。
- Worker收到指令后创建ExecutorRunner线程,ExecutorRunner线程内部启动ExecutorBackend进程
- ExecutorBackend启动后,向Client端Driver进程内的SchedulerBackend注册,这样Dirver进程就可以发现计算资源了。
- Driver的DAGScheduler解析应用中的RDD DAG并生成相应的Stage,每个Stage包含的TaskSet通过TaskScheduler分配给Executor,在Exectutor内部启动线程池并行化执行Task
- 当所有Stage被执行完了之后,各个Worker汇报给Driver,同时释放资源,Driver向Master汇报,同时由于Driver在Client上,Clinet也知道应用的执行进度。
(2)Driver进程在Work节点运行
执行流程如图3所示,

- 客户端提交应用程序给Master
- Master调度应用,指定一个Worker节点启动Driver。
- Worker接收到Master命令后创建RriverRunner线程,在DriverRunner线程内创建SchedulerBackend进程,Dirver充当整个作业的主控进程。
- Master指定其他Worker节点启动Exeuctor,Worker创建ExecutorRunner线程,启动ExecutorBackend进程,剩下流程与上面类似,不再赘述。
